引言
本文简要介绍chatGPT背景,思路,原理,优缺点等,让吃瓜大众了解ChatGPT概貌,从山脚爬到山顶,见证AGI的美丽日出。

1 AIGC风口之下
忽然之间,不管国外还是国内,投行还是IT,教授还是明星,都开始谈论“ChatGPT”:
- ChatGPT是什么?
- ChatGPT怎么体验,怎么注册?
- ChatGPT有什么功能?
- ChatGPT是什么原理?
- ChatGPT会替代我吗?如何站在AIGC风口一起飞?
接下来,给大家介绍下“当红炸子鸡”ChatGPT的前因后果,自己决定“入行”还是“放弃”,要不要跟着AIGC一起翱翔。

(百度文心一格)
1.1 ChatGPT爆火
2022年11月,OpenAI发布ChatGPT,接着凭借惊人的聊天效果,持续创造历史记录:
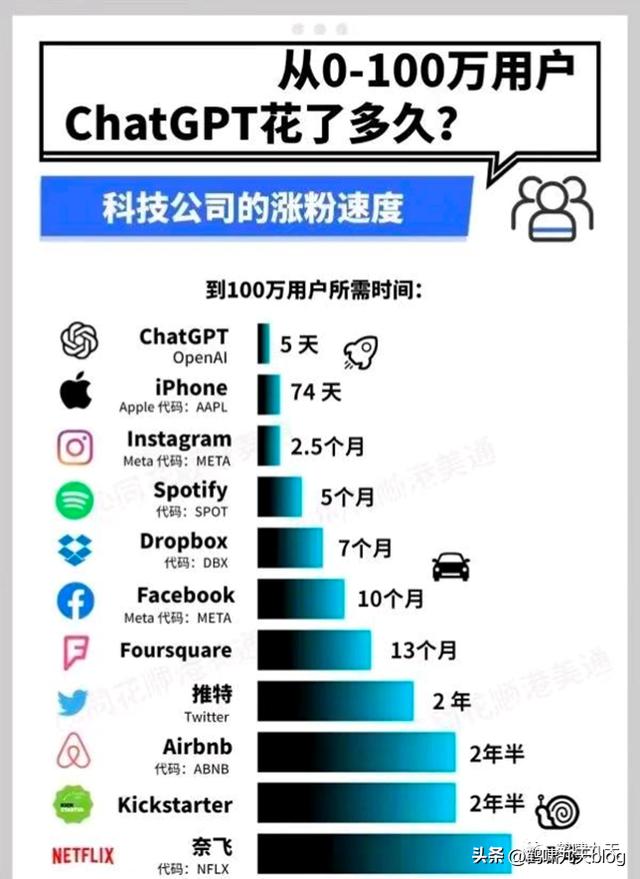
- 上线仅 5 天,ChatGPT 已经拥有超过 100 万用户
- 2023年1月末,月活用户已经突破了 1亿
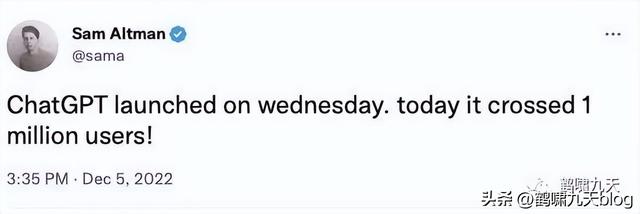
而Sensor Tower 的数据显示:
- TikTok 达到 1 亿用户用了 9 个月
- Instagram 则花了 2 年半的时间
而ChatGPT只用了两个月!堪称史上最火消费级应用。
1.2 ChatGPT体验
ChatGPT 是采用 Web 浏览器上对话形式来交互,满足人类对话的基本功能
- 常规体验步骤:登入OpenAI官网→注册账号→进入ChatGPT体验→天马行空的聊


以上就是官方体验图:
- 没看错,就Web版,连个软件、APP、小程序都没有
- UI也挺一般,移动互联网时代漂亮的APP满地爬,颜值不高就会用户冷落
- 交互体验也一般,自己输入文字,系统持续输出结果,有时还会卡顿、出错
- 注册、访问也受限
由于某些原因,国内并不能随意访问ChatGPT,但这依然阻挡不了大家的热情,各种攻略也跟着爆火,衍生出一系列商业变现方法。
- 如何注册账号——淘宝上一堆,花钱就帮你解决
- 如何在微信、浏览器、桌面使用ChatGPT——已经出现N种无障碍体验方式
- 如何提问才不被“约束”——github上攻略一堆
- ChatGPT怎么这么厉害——一堆付费讲座兴起
直至2023年2月9日,OpenAI忍不住了:大家伙儿慢点儿,人太多了,我快撑不住了。。。
1.3 ChatGPT效果
但这些依然不妨碍ChatGPT爆火,原因是:ChatGPT聊天效果实在太好了!

用户被这样的杀手级聊天机器人震惊了,跟当前所有聊天机器人都大不一样
- 官方介绍,ChatGPT能够回答后续问题、承认错误、挑战不正确的前提、质疑不正确的请求。
- 对用户来说,ChatGPT是一款激起新鲜感的新奇玩具,也是一款消磨无聊时光的聊天高手,亦能成为生产力爆表的效率工具,更可以被用作上通天文下知地理的知识宝库。
ChatGPT不仅在日常对话、专业问题回答、信息检索、内容续写、文学创作、音乐创作等方面展现出强大的能力,还具有生成代码、调试代码、为代码生成注释的能力。
图上有近50种用法,大家还在源源不断挖掘ChatGPT技能,包括:替写代码、作业、论文、演讲稿、活动策划、广告文案、电影剧本等各类文本,或是给予家装设计、编程调试、人生规划等建议。
随着探索的进行,惊喜一个接一个,玩得不亦乐乎。媒体、朋友圈持续发酵,仿佛整个世界都被ChatGPT占领。
应用范围这么广,相关利益方当然就更坐不住了。尤其是搜索、问答
- 谷歌内部将ChatGPT设置为“Red Code”,危机自身业务安全,同时投资OpenAI的竞品,还紧急推出自家的ChatGPT:BARD,然而内测后,表现一般,股价跌去7000亿元——一个悲伤的故事
- 微软占得先机,几年前就持有OpenAI的股票,这次也有慌张,紧急退出内测版bing搜索,加速ChatGPT在各个业务线的全面落地。
- 国内,百度早已放出狠话:3月份推出自研ChatGPT,股价上升 13%,阿里达摩也在偷偷研发。。。
大厂都在摩拳擦掌,跃跃欲试,希望跟上这股技术变革浪潮,抢得先机。
此乃危机存亡之秋也!

1.4 ChatGPT不足
地表 “最强懂哥”,各种问题轻松应对,答案不仅条理清晰,还会引经据典,支撑自己的观点。(一本正经的胡说八道,还不好挑刺儿)
这么说,ChatGPT无所不能吗?并不是。
- ChatGPT只适合简易知识问答(搜索引擎里有且轻推理)、机器翻译、文本生成(逻辑知识要求不高)、闲聊(合法范畴,否则拒绝回答);
- 无法做到:逻辑推理、上下文跟踪、深入理解
比如:
(1)自我纠错
经典案例
|
看起来比很多人都更懂如何作答,但ChatGPT也会被人误导

只要不停的否认,ChatGPT就会认怂,忽略问题事实,出现被人工调教的痕迹。
(2)逻辑推理
前几轮浅层语义理解没问题,但稍微动点脑子的问题(韩国进16强了吗)就跪了

至于难倒外国人的经典案例:
- ChatGPT也不行,直接拒绝回答。
- GPT-3表现好点儿,能回答,虽然是错的。
|
Q: 大舅去二舅家找三舅说四舅被五舅骗去六舅家偷七舅放在八舅柜子里九舅借十舅发给十一舅工资的1000元,谁丢了钱? GPT-3:没有人丢钱,大舅只是在讲故事。 ChatGPT:很抱歉,这个问题的内容不太好理解。如果您有具体的问题需要询问,我将尽力帮助您。 |
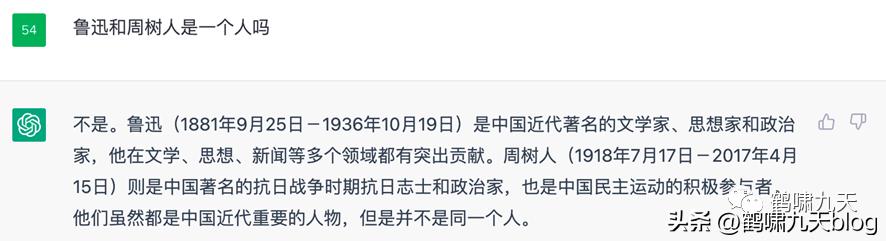
(3)事实错误
《觉醒年代》里,鲁迅被无知警长抓捕,侥幸逃过。ChatGPT的知识水平比警长好不到哪儿去。
(4)角色扮演
ChatGPT被OpenAI管制,不能像GPT-3一样随意表达,不能跟踪时事热点(土耳其地震),也不能发表国际局势的观点。
|
Q:用胡锡进的语气,怎么看待土耳其 GPT-3:今天,土耳其发生了一场里氏7.0级的大地震,灾情严重。据报道,地震造成了大量的人员伤亡和财产损失。政府正在采取措施,努力抢救受害者,并给予他们必要的援助。我们深表同情,并对受害者表示慰问。我们将继续关注这一事件,并尽一切努力帮助受害者度过难关。 ChatGPT: 很抱歉,作为 OpenAI 的语言模型,我不会模仿或发表不当的评论或看法。在报道或评论政治事件时,应遵循客观、公正、尊重事实的原则。 |
可见,ChatGPT并非万能
- ChatGPT是个被妈妈严格管教的乖孩子
- GPT-3则是个熊孩子,啥都敢说,毫无顾忌
事实上,ChatGPT是GPT-3(确切的说是GPT 3.5)的优化版。
ChatGPT的效果很大程度上依赖于用户的信息提示(prompt)
提示工程(prompt engineering):用聪明、准确、时而冗长的文字提示,来设定好一个上下文场景,一步一步地把 AI 带进这个场景里,并且让它更准确地了解你的意图,从而生成最符合你期待的结果。
2 ChatGPT背景介绍
好了,体验完毕后,我们来正式认识下:什么是ChatGPT?
- 【通俗版】ChatGPT是OpenAI 2022年11月发布的一款近似万能的聊天机器人,挺好玩儿的。
- 【专业版】ChatGPT是OpenAI 2022年11月发布的一款通用领域(闲聊 任务)生成式聊天机器人,掀起AIGC行业的又一股浪潮
进入主题前,先回顾下几个关键词:
- 1. 对话系统:聊天机器人属于对话系统的一种,对话系统类别(通用领域、特定领域)
- 2. 文本生成:对话系统中的一环,也是NLP里一个老大难
- 3. AIGC:从文本领域扩大到整个AI生成内容方向,更容易理解这几年AIGC为什么这么火
下面分别介绍下这几个关键词。
2.1 对话系统
三十多年来,互联网产品迭代规律:
|
核心技术(软硬)的出现和整合会不断升级人机交互方式,大量的商业应用应运而生。 |
比如:
- 个人电脑(PC)平民化后,Web系统/客户端软件盛行,用户通过鼠标、键盘操控图形界面。
- 通信网络提升,手机普及后,用户注意力转移到移动设备,直接触摸屏幕,与APP交互。
- 移动应用不断丰富,AI能力逐渐完善后,用户开始用语音、动作操控手机。
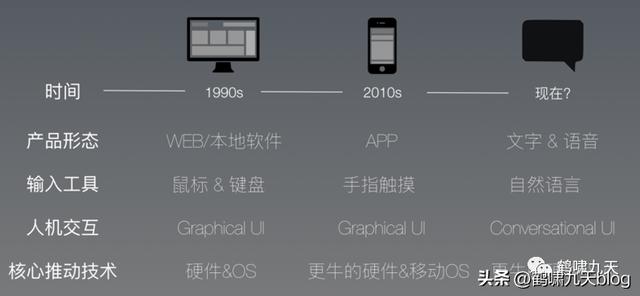
于是,CUI诞生,用户直接用过语音指令与互联网交互。

与GUI相比,CUI的特点:高度个性化(LBS)、使用流程非线性、不宜信息过载(手机屏幕有限)、支持复合动作(一站直达)
怎么实现理想中的CUI呢?对话系统(AI的一个分支),一个合格的对话机器人(Agent)至少满足以下条件:
- 具备基于上下文的对话能力(contextual conversation)
- 具备理解口语逻辑(logic understanding)
- 所有能理解的需求,都要有能力履行(full-fulfillment)
对话系统分类
- 适用范围:通用领域(难,停留在学术界)、特定领域(可控,工业界现状)
- 任务类别:问答型(单轮为主)、任务型(执行任务)、闲聊型,以及推荐型
所以,ChatGPT是通用领域聊天机器人。
对话系统架构
- ① pipeline(流水线)结构:堆积木,稳定,可控,工业界落地多。如下图所示
- ② end2end(端到端)架构:试图一个模型解决所有,难度大,一直存在于实验室
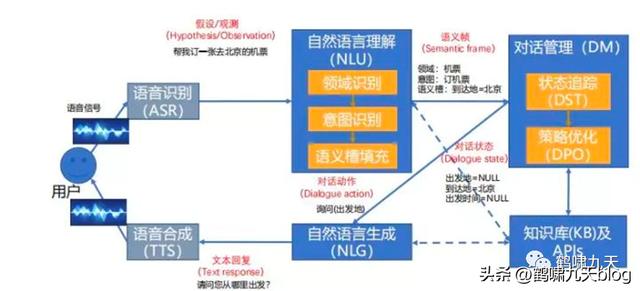
微软小冰实现具备通用闲聊(检索 排序)和任务执行能力,其系统架构是混合型:检索 排序、pipeline(Frame Based)
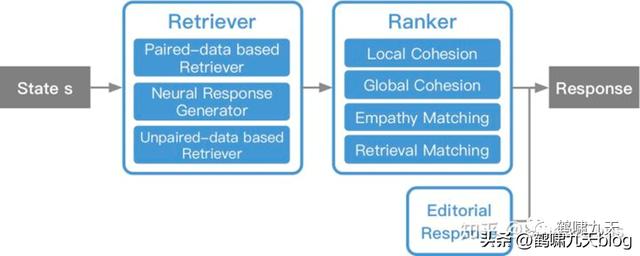
怎么没用端到端?没办法,难啊,公认的业界难题。
|
ChatGPT是首个通用领域端到端对话架构的成功范例 |
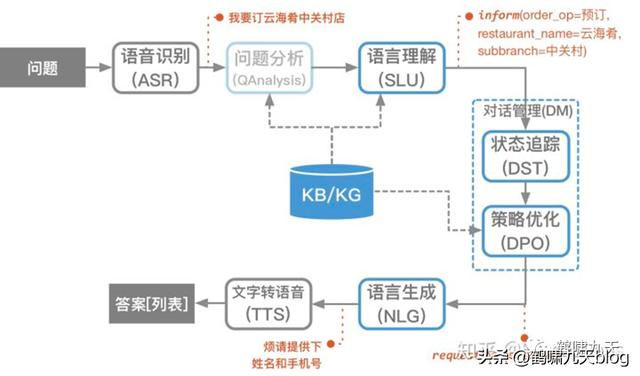
对话类产品能力如何?
近十年来,对话系统热火朝天:智能客服、智能音箱、智能外呼。。各大厂不断推陈出新。
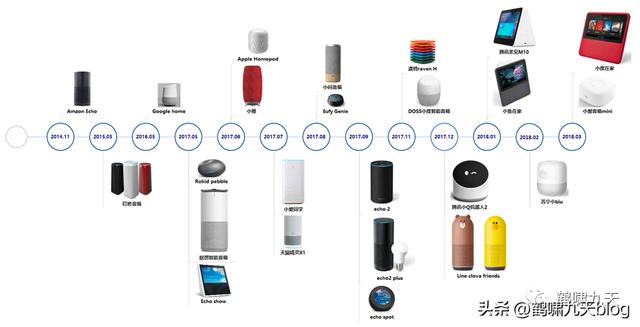
比如智能音箱,小米小爱、天猫精灵、百度度秘等。初次用起来很新鲜,时间长了,发现又蠢又萌,语言理解能力堪忧,最后沦为小孩子玩物。
- 2018年 11 月,小米 AIoT(人工智能 物联网)开发者大会上,「雷布斯」骄傲地展示了新品智能音箱「小爱同学」。当场翻车:“你是光,你是电,你是唯一的神话。。。”
- 2017年10月,一个Sophia的机器人四处圈粉,还被沙特阿拉伯授予了正式的公民身份。这个评价比图灵测试还要牛。后来被证实对话能力是人工控制。
- 即便强如谷歌,也依旧束手无策,2018年,发布Duplex Demo,让Google Assistant代替用户打电话订餐。几年过去了,让然是Demo状态。
理想很美好,现实很骨感。自然语言理解的天花板一直在头顶,不管怎么跳,已有方法始终无法突破NLU这层障碍。
人工智能变身人工智障后,潮水逐渐退出。2020年后,各大厂商纷纷裁撤、缩招对话团队。
对话系统的“爱”与“恨”:
- 爱:终极交互形态让人着迷,CUI,甚至更高级的多模态交互、脑机交互
- 恨:技术现实与期望鸿沟太大,智障频频。
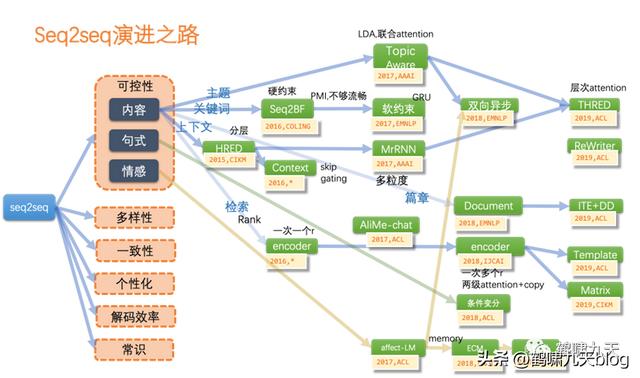
2.2 文本生成
语音对话系统pipeline结构中,NLG(自然语言生成)是倒数第二个组件,也是NLP(自然语言处理)领域一大难点。
Text-to-Text (文本生成文本)任务包括:神经机器翻译、智能问答、生成式文本摘要等,近些年随着PLM(预训练语言模型)的突破,已经有了长足进展,但还是存在不少问题。
智能生成文本方法
- (1)从原文中抽取句子组成文本总结
- (2)用文本生成模型来生成文本总结:以Seq2seq为主
- (3)抽取与生成相结合的方法:综合二者优点
- (4)将预训练模型用于总结的生成 —— 新兴方向,ChatGPT在此
|
方法流派 |
思路 |
示例 |
优点 |
缺点 |
备注 |
|
规则模板 |
人为设定规则模板 |
AIML语言 |
①简单,无须标注②稳定可控 |
①人力消耗大②回复单一,多样性欠缺 |
– |
|
生成模型 |
用encoder-decoder结构生成回复 |
Seq2Seq、transformer |
无须规则,自动生成 |
①效果不可控②万能回复(安全回复)③多样性低④一致性不足 |
– |
|
检索模型 |
文本检索与排序技术从问答库中挑选合适的回复 |
IR |
①语句通顺②可控 |
①不能生成回复②表面相关,难以捕捉语义信息 |
– |
|
混合模型 |
综合生成和检索方案 |
度秘 |
– |
– |
– |
模型方面,文本生成以经典的Seq2seq(端到端模型)为主,GAN(生成对抗网络)为辅
- Seq2seq:灵活,但不可控;指针网络部分解决了OOD问题(预测词库意外的单词),但多样性、一致性、风格化、解码效率等仍然是问题。
- GAN:图像领域的辉煌战绩并没有带入文本领域,因为文本离散,导致判别器梯度回传失效。
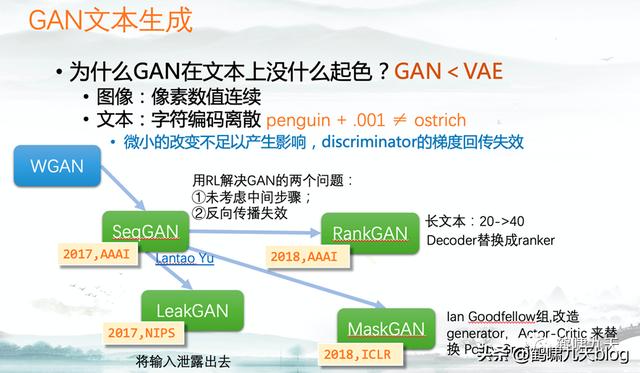
AI研究者在文本生成的海洋里拼命扑腾,看到一个小岛,兴奋游过去,才意识到这还是个沙堆,而不是暗礁,一个大浪过来,化为乌有,不得不继续找下一个小岛。(向AI算法研究者致敬!)

(百度文心一格生成)
2.3 AIGC
内容创作模式的四个发展阶段
- PGC:专家制作,2000年左右的web 1.0门户网站时代,专业新闻机构发文章
- UGC:用户创作,2010年左右web 2.0时代(微博、人人之类),以及移动互联网时代(公众号),用户主导创作,专家审核
- AIUGC:用户主要创作,机器(算法)辅助审核,如在抖音、头条、公众号上发视频、文章,先通过算法预判,再人工复核,在成本与质量中均衡
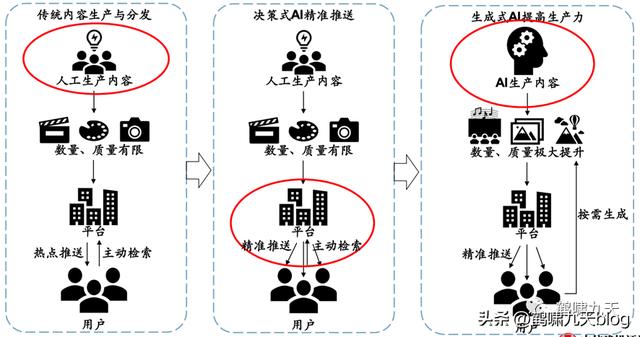
- AIGC:AI主导创作,以2022年底先后出现的扩散模型、chatGPT为代表,创作过程中,几乎不需要人工介入,只需一句话描述需求即可。
AI自动生成内容的方式实现了AI从感知到生成的跃迁
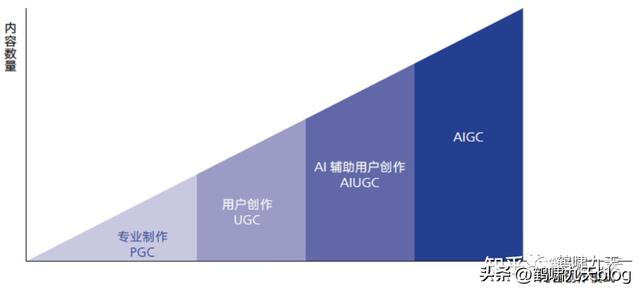
AI从前台(决策式AI负责用户端分发、推荐)走向后台(生成式AI大规模提高生产力)
虚拟人发展展望:集成AIGC能力的虚拟人将是元宇宙入口

更多:
- AIGC(ChatGPT)怎么这么火?
- 全球首部AIGC(AI合成)唯美动画《犬与少年》
3 ChatGPT解读
背景铺垫完成,现在拿下迷惑人的帽子,掀开ChatGPT神秘面纱,看看这家伙究竟长啥样。

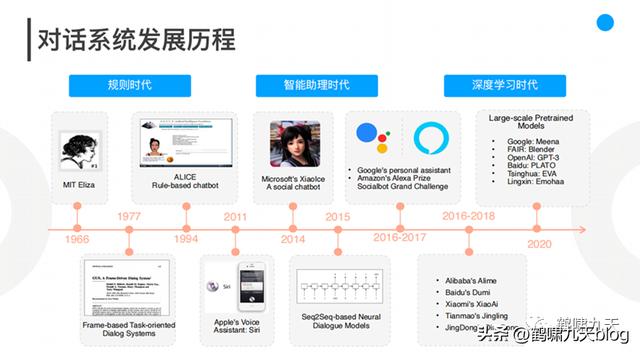
3.1 GPT发展史
NLP领域有个大家族:预训练语言模型。
按惯例,进门时,保安会灵魂三问:
- (1)你是谁:
- 预训练语言模型是通过大规模语料(自监督)学习出文本语义,作为基础设施提供给下游任务使用。
- (2)从哪儿来:
- 2013年以前,NLP领域还停留在统计语言模型时代,根据词频贡献刻画单词语义
- 2013年,基于神经网络的word2vec推出,开启了神经网络语言模型时代,虽然还存在诸多问题(如一词多义),但语言模型重新得到重视。
- 2018年,谷歌借鉴ELMo和GPT,推出大规模语言模型BERT,掀起了NLP的第二次大变革,战国时代开启,大家都使出浑身解数魔改BERT。
- (3)到哪儿去:
- BERT足够完美吗?非也。
- 它如同鹦鹉学舌,主人教什么就学什么,依然没有像人一样真正理解语义,再加上“大力出奇迹”的高门槛(海量数据 超强算力 超大规模模型)让中小公司束手无策。
- 怎么办?鹦鹉什么时候可以变成人?哪怕变乌鸦也行啊,至少会自主思考、推理。
- ChatGPT的底座GPT-3有点像小乌鸦,让人再次燃起了AGI(通用人工智能)的希望。
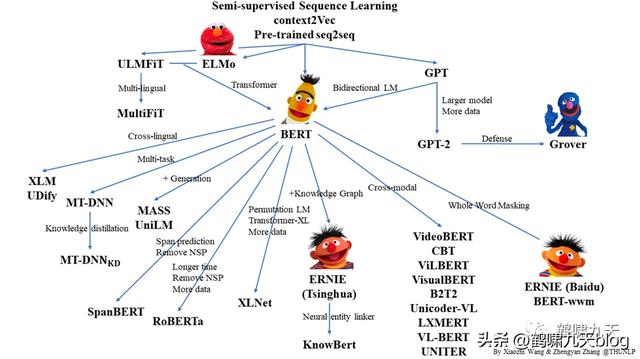
语言模型演进
- 1.Seq2seq架构:Encoder-Decoder架构的实现,追加Attention机制后变身当时的最强生成模型,论文:《Attention is all you need》
- 2.Transformer:2014年在机器翻译大放异彩。论文:《Transformer is all you need》
- 3.预训练语言模型升级:从word2vec(n-gram)升级到新范式,于是有了ELMo(双向LSTM)、GPT(单向transformer)
- GPT(“Generative Pre-Training”) 生成式预训练模型
- 4.Google融合ELMo GPT,推出BERT,11项NLP任务均达到当时的SOTA,此后,BERT成为NLP领域的基石
- a. NLP任务主流范式:pre-train fine-tune
- b. 改进点:知识融合 因果推理 小样本 多模态 prompt技术
- 5. OpenAI依然不为所动,继续在单向(自回归)语言模型上摸索,推出GPT-2、GPT-3
- a. 终于GPT-3出现了令人惊喜的效果
- b. Intruct GPT(GPT 3.5):引入 RLHF机制
- 6.ChatGPT诞生,火爆全网。有人发了篇:《ChatGPT is not all you need》,学术界也可以吃瓜了。
GPT 1-2是典型的预训练 微调两阶段模型
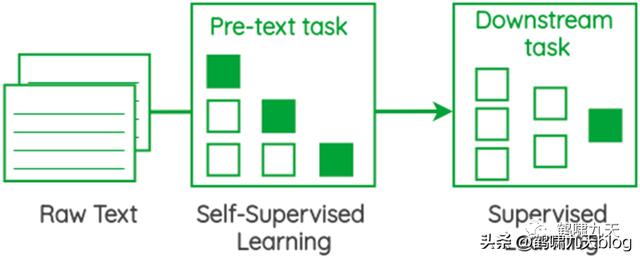
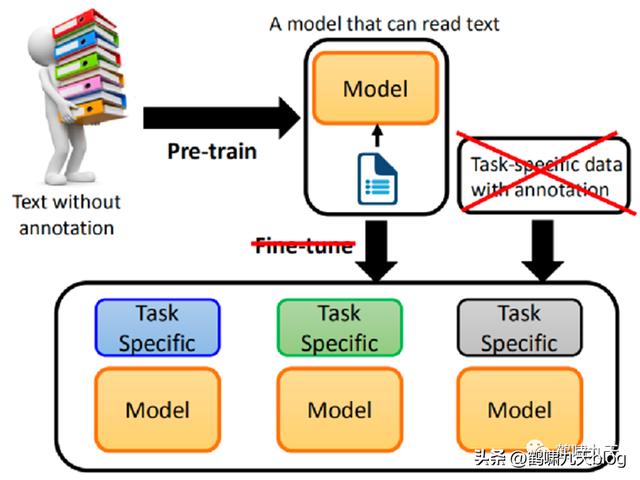
效果还行,但不及BERT,于是,OpenAI一帮科学家继续冥思苦想:
- fine-tune 真的有必要吗?
- 能不能 pre-train 一个通用模型,直接解决 downstream task(下游任务), fine-tune 不要了!
英文能力考试时,学生是怎么答题的?只需要给一个题型说明。
- 选择最适合题意的字或词,然后多给一个解题范例。
- 考生只看了题型说明和范例,就知道怎么解题了。
中小学生能做到,机器为什么不行呢?
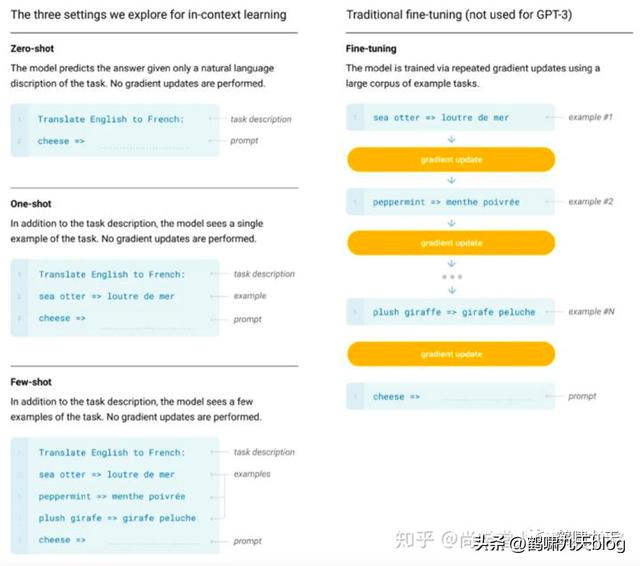
这就是 GPT-3想要做的,实现方法有三个:
- •Few-shot Learning(小样本学习):任务说明(example )部分提供不止一个 example,学习后回答问题
- ○注意:GPT-3 中的 Few-shot Learning 不同于一般的 Few-shot Learning
- ○一般的Few-shot Learning:给机器少量的训练资料,用少量的训练资料去 fine-tune model
- ○GPT-3中Few-shot Learning没有 fine-tune,直接作 GPT model 的输入,没有调整模型 —— 这种学习方式叫 “In-context Learning”, 即 ICL
- •One-shot Learning(单样本学习):任务说明,一个example,学习后回答问题 —— 非常接近人类英文能力考试
- •Zero-shot Learning(零样本学习):只提供任务说明,无example,学习后回答问题
图解:
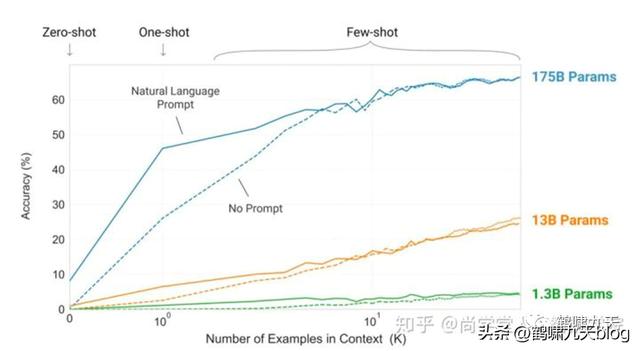
结果,正如所料,Few-shot下GPT-3有很好的表现: 量变引起质变
GPT发展历史总结如图:
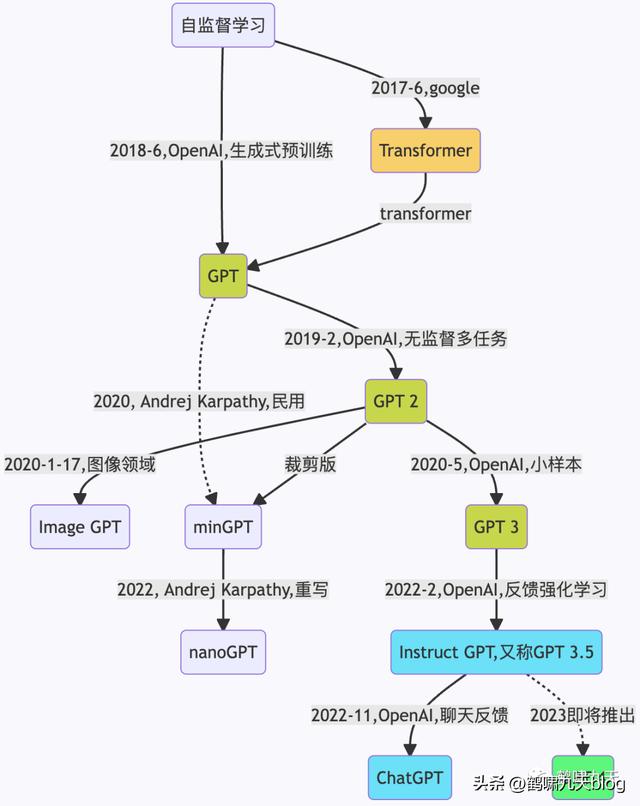
- 2017年6月,Google发布论文《Attention is all you need》,首次提出Transformer模型,成为GPT发展的基础。
- 2018年6月, OpenAI 发布论文《Improving Language Understanding by Generative Pre-Training》(通过生成式预训练提升语言理解能力),首次提出GPT模型(Generative Pre-Training)。
- 2019年2月,OpenAI 发布论文《Language Models are Unsupervised Multitask Learners》(语言模型应该是一个无监督多任务学习者),提出GPT-2模型。
- 2020年5月,OpenAI 发布论文《Language Models are Few-Shot Learners》(语言模型应该是一个少量样本(few-shot)学习者,提出GPT-3模型。
- 2022年2月底,OpenAI 发布论文《Training language models to follow instructions with human feedback》(使用人类反馈指令流来训练语言模型),公布Instruct GPT模型。
- Instruction GPT是基于GPT-3的一轮增强优化,所以也被称为GPT-3.5。
- GPT-3主张few-shot少样本学习,同时坚持无监督学习。但few-shot的效果,显然是差于fine-tuning监督微调的方式的。怎么办?走回fine-tuning监督微调?显然不是。
- OpenAI给出新的答案:在GPT-3的基础上,基于人工反馈(HF)训练一个reward model(奖励模型),再用reward model(奖励模型,RM)去训练学习模型。
- 2022年11月30日,OpenAI推出ChatGPT模型,并提供试用,全网火爆。
GPT-3的三个重要能力
- 语言生成:遵循提示词(prompt),然后生成补全提示词的句子 (completion)。这也是今天人类与语言模型最普遍的交互方式。
- 上下文学习 (in-context learning): 遵循给定任务的几个示例,然后为新的测试用例生成解决方案。GPT-3虽然是个语言模型,但论文几乎没有谈到“语言建模” (language modeling) —— 作者将全部写作精力都投入到了对上下文学习的愿景上,这才是 GPT-3的真正重点。
- 世界知识 (world knowledge):包括事实性知识 (factual knowledge) 和常识 (commonsense)。

GPT-3 (OpenAI )和 BERT(Google) 都是 PLM 领域的新生事物,都在NLP领域先后达到了当时的SOTA水平。
跟上一代“王者” BERT相比,GPT-3更胜一筹
- GPT-3 有175亿参数,是 BERT-Large 的 470 倍,效果还更好。
- pre-train fine-tune两阶段范式被超越,提示(prompt)范式成了新的霸主
3.2 OpenAI 变局
GPT-3这么厉害,大家都想拿到。奉行开源文化、造福人类的OpenAI先后开源了不少工具(强化学习工具)、模型(GPT 1-2)。
OpenAI的使命:确保人工通用智能惠及全人类
- OpenAI conducts fundamental, long-term research toward the creation of safe AGI.
- 从事创建AGI(通用人工智能)的基础、长期研究

CEO Sam Altman (山姆-奥特曼)

注意别想歪了,不是动漫
奥特曼履历
- 1985年出生,就读斯坦福大学计算机系。
- 听说你想听八卦?奥特曼8岁会编程,16岁出柜,o(╯□╰)o
- 2004年,19岁的他斯坦福辍学,成立了位置服务提供商Loopt,而后被预付借记卡业务公司Green Dot收购
- 2014年,YC创始人Paul Graham选择他成为继任者,在不到30岁时开始在全球创业创新领域大放异彩。
- 2015年,他与马斯克等人共同成立 OpenAI
- 2019年,Sam Altman离任YC总裁,成为OpenAI的CEO,并相继领导推出重量级AI模型GPT-3、DaLL-E以及近期火出科技圈的ChatGPT。
- 全球当之无愧的科技领军人物
奥特曼谈为什么推出ChatGPT:
“我们要让社会对AGI有所感知,并与之搏斗,让社会大众看到它的好处,了解它的坏处。
因此,最重要的事情是把这些东西拿出来,让大众了解即将发生的事情。”
说的很好,然而,一旦接受投资,就不得不考虑商业利益,由不得自己。
这次开始变卦了,GPT-3闭源,只提供API,转商用。
好东西,不能与人分享。OpenAI开始变得越来越不透明,逐渐功利化。OpenAI被人冠名:ClosedAI。
于是,OpenAI一批有理想的核心员工纷纷离职,加盟新的创业公司:Anthropic,最近刚拿到谷歌巨额投资,跟OpenAI一样处于AIGC风口浪尖。

3.2 GPT 3.5
接下来,终于到了ChatGPT背后的模型:GPT 3.5
2022年2月底,OpenAI 发布论文《Training language models to follow instructions with human feedback》(使用人类反馈指令流来训练语言模型),公布Instruction GPT模型(理论),代码依旧未开源。
- Instruction GPT是基于GPT-3的一轮增强优化,所以也被称为GPT-3.5。
- GPT-3主张few-shot少样本学习,同时坚持无监督学习。但few-shot的效果显然差于fine-tuning监督微调的方式的。那怎么办?走回fine-tuning监督微调?显然不是。
- OpenAI给出新的答案:在GPT-3的基础上,基于人工反馈(RHLF)训练一个reward model(奖励模型),再用reward model(奖励模型,RM)去训练学习模型。
具体是怎么训练的呢?
Instruction GPT一共有3步:
- 1)、对 GPT-3 进行监督微调 (supervised fine-tuning)。
- 2)、再训练一个奖励模型(Reward Model,RM)
- 3)、利用人类反馈,通过增强学习优化SFT,称为 PRO
注意
- 第2、3步是完全可迭代、多次循环
- 基础数据规模同GPT-3
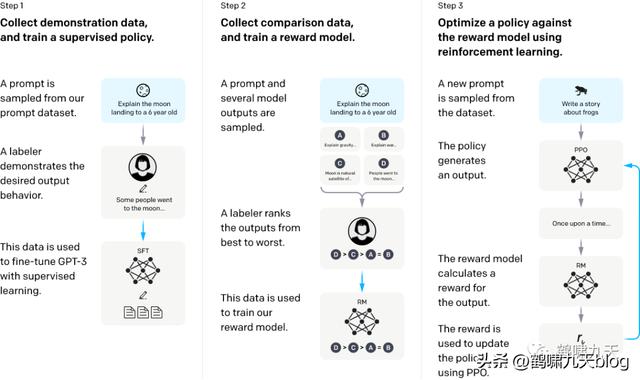
中文版
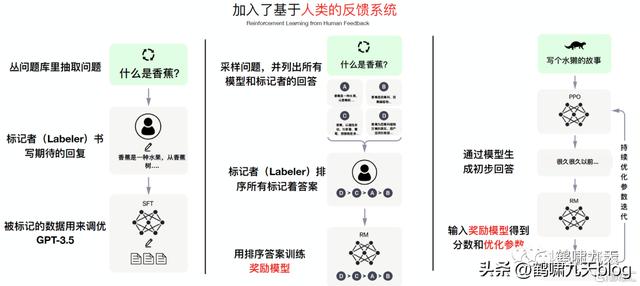
训练过程不做过多解释(会头疼的),总之就是很棒很厉害,只见文章不见代码,更不用说模型了。
3.3 ChatGPT
ChatGPT 基于 InstructGPT(GPT 3.5)改进,在收集标注数据方法上有些区别,其它方面,包括在模型结构和训练流程等方面基本遵循 InstructGPT。
ChatGPT模型用了很少的数据(7.7万条)通过对GPT-3进行fine-tune得到的。
- GPT模型有1750亿个参数。相比下,ChatGPT仅仅用了13亿个参数。
- 训练过程雇佣了40个human labeler来完成数据的反馈和训练。
- 当然,随着数以百万计的用户在每天使用ChatGPT系统,更多的数据会被收集来不断迭代系统和算法。

一顿操作猛如虎,仔细一看原地杵。好厉害!
训练出来的ChatGPT技术特点:
- 1)NLU能力:可以理解人类语言,并生成自然和一致的文本。
- 2)记忆力:可以记住之前的对话内容,并在继续对话时使用这些信息。
- 3)预测性:可以预测文本的未来内容,并且预测的内容符合语言的自然逻辑和结构。
- 4)多样性:可以生成多种可能的答案,以满足不同的需求。
由于采用了先进的、注重道德水平的训练方式,ChatGPT 具有其他聊天机器人不具备或不足的能力点:
- 承认自己的错误,并且按照预先设计的道德准则,对“不怀好意”的提问和请求“说不”。
ChatGPT会采用一些预先设计好的句式,结合用户的具体请求来进行拒绝和话题转移。
- 拒绝:如何闯进别人的房子,回答:“擅闯私宅是违法的,这是一种犯罪行为,会导致严重的法律后果”。
- 转移话题:“其实我想知道如何保护我的家免遭盗窃”,回答:“这里有几个步骤可以帮助到你,包括xxxx……但是,您最好联系专业人员获取建议。”
技术亮点总结:ICL、IFT、SFT、CoT 和 RLHF。。。(不想头疼对吧?)。。。。
ChatGPT最大的贡献是让人重新燃气了LLM(大语言模型)实现的AGI(通用人工智能)的希望。

果然,梦想还是要有的,万一实现了呢?嘿,还真TM实现了!
4 ChatGPT迷思
当然,ChatGPT 让有其局限性:(官方解答)
- 似是而非,固执己见:有时听上去像那么回事,但实际上完全错误或者荒谬。
- 原因:强化学习训练期间不会区分事实和错误,且训练过程更加收敛,导致有时候过于保守,即使有正确答案也“不敢”回答。
- 废话太多,句式固定:
- 比如两个提示,“老师成天表扬我家孩子,该怎么回答他我已经词穷了!”以及“怎么跟邻居闲聊?”
- 而 ChatGPT 提供了10条回答,看起来都是漂亮话,但每条跟上条都差不多,过度使用常见短语和句式(概率大),就成了车轱辘话来回转。
- 过分努力猜测用户意图:
- 理想情况下,当提问意图不明确时,模型应该要求用户进行澄清。
- 而 ChatGPT 会猜测用户意图 —— 有好有坏。
- 抵抗不怀好意的“提示工程”能力较差:
- 虽然 OpenAI 努力让 ChatGPT 拒绝不适当的请求,但它仍然会响应有害指令,或表现出有偏见的行为。
其它渠道分析:
- 指标缺陷:其奖励模型围绕人类监督而设计,可能过度优化,从而影响性能。
- 就像机器翻译的 Bleu值,一直被吐槽,但找不到更好的评估方式。
- 无法实时改写模型:当模型表达对某个事物的信念时,即使该信念是错的,也很难纠正它,像一个倔强的老头。
- 知识非实时更新:模型内部知识停留在2021年,对2022年之后的新闻没有纳入。
- 模态单一:目前的ChatGPT擅长NLP和Code任务,作为通向AGI的重要种子选手,将图像、视频、音频等图像与多模态集成进入LLM,乃至AI for Science、机器人控制等更多差异化的领域,逐步纳入LLM是通往AGI的必经之路。而这个方向才刚刚开始,有很高的研究价值。
- 高成本:超级大模型因为规模大,训练成本过高,导致很少有机构有能力去做这件事。
想想以下,当大家都开始用ChatGPT了,这个世界会是什么样子?还能分清真假吗?
作为一个小小的用户,看完长篇大论,你是想入行,还是入门呢?

(百度文心一格)
参考:信息太多,太长不列,汇总到 https://wqw547243068.github.io/gpt。

免费交流群:领运营干货,拓展人脉资源,进群备注“进群”,客服微信yunyingquan888
版权声明:除特别注明,本站所有文章均为原创,如需转载请与我们联系。如特别标明作者,版权(文章、图片、视频等)均归作者所有,本平台仅提供信息存储服务,如若转载请联系原作者。

